Natural Language Processing (NLP) for Beginners
Natural Language Processing (NLP) for Beginners
Introduction to NLP
Natural Language Processing (NLP) stands at the fascinating intersection of artificial intelligence, computer science, and linguistics. It is a field dedicated to enabling computers to understand, interpret, and generate human language in a way that is both meaningful and useful. In essence, NLP aims to bridge the communication gap between humans and machines, allowing computers to process and make sense of the vast amounts of text and speech data that humans produce daily.
Historically, the challenge of teaching computers to understand human language has been immense. Human language is inherently complex, filled with ambiguities, nuances, and context-dependent meanings. Words can have multiple meanings (polysemy), and the same meaning can be expressed in various ways (synonymy). Sarcasm, irony, and figurative language further complicate interpretation. Early attempts at NLP relied heavily on rule-based systems, which involved manually coding linguistic rules. While these systems had some success in narrow domains, they struggled to scale and adapt to the richness and variability of natural language.
The advent of machine learning and, more recently, deep learning has revolutionized NLP. Instead of explicit rules, modern NLP models learn patterns and relationships from large datasets of text and speech. This data-driven approach has led to significant breakthroughs in various NLP tasks, from language translation and sentiment analysis to chatbots and voice assistants. The ability of computers to process and understand human language has profound implications across numerous industries, transforming how we interact with technology and extract insights from unstructured data.
Fundamental Concepts: Tokenization, Stemming, Lemmatization, and Stop Words
Before a computer can understand human language, it must first process and prepare the raw text data. This involves several fundamental steps that transform unstructured text into a more structured and analyzable format. Understanding these concepts is crucial for anyone venturing into NLP.
Tokenization
Tokenization is the process of breaking down a continuous sequence of text into smaller units called
tokens. These tokens can be words, phrases, symbols, or other meaningful elements. For example, in the sentence “The quick brown fox jumps over the lazy dog.”, tokenization would break it down into individual words: “The”, “quick”, “brown”, “fox”, “jumps”, “over”, “the”, “lazy”, “dog”, and the punctuation mark ”.”. Tokenization is a foundational step in almost all NLP tasks, as it provides the basic units for further analysis. Different tokenization strategies exist, depending on the language and the specific NLP task. For instance, some tokenizers might separate punctuation, while others might keep it attached to words.
Stemming
Stemming is a crude heuristic process that reduces words to their root or base form, known as a “stem.” The goal of stemming is to group together words that have similar meanings but different grammatical endings. For example, the words “running,” “runs,” and “ran” might all be reduced to the stem “run.” While stemming is simpler and faster to implement, it often produces stems that are not actual words. For instance, “beautiful” might be stemmed to “beauti.” This can sometimes lead to a loss of meaning or inaccurate results, but for many applications, the speed and simplicity of stemming make it a viable option.
Lemmatization
Lemmatization is a more sophisticated and linguistically informed process than stemming. It aims to reduce words to their base or dictionary form, known as a “lemma.” Unlike stemming, lemmatization considers the word’s morphological analysis to ensure that the resulting lemma is a valid word. For example, “running,” “runs,” and “ran” would all be lemmatized to “run,” just like with stemming. However, “better” would be lemmatized to “good,” and “caring” to “care.” Lemmatization typically requires a dictionary or a lexical knowledge base, making it more computationally intensive but also more accurate than stemming. It is preferred in applications where linguistic accuracy is critical, such as machine translation or question answering systems.
Stop Words
Stop words are common words in a language that carry little to no significant meaning and are often removed from text before processing. These words, such as “the,” “a,” “is,” “and,” “in,” etc., appear frequently but do not contribute much to the overall sentiment or topic of a document. Removing stop words helps to reduce the dimensionality of the data, improve the efficiency of NLP algorithms, and focus on the more important, content-bearing words. While there isn’t a universal list of stop words, most NLP libraries provide default lists that can be customized based on the specific application and domain.
Common NLP Tasks: Sentiment Analysis, Text Classification, and Named Entity Recognition
With the fundamental concepts in place, NLP enables a wide array of powerful applications. Here are some of the most common and impactful NLP tasks:
Sentiment Analysis
Sentiment analysis, also known as opinion mining, is the process of determining the emotional tone behind a piece of text. It aims to identify and extract subjective information from source materials, such as opinions, attitudes, and emotions. Sentiment analysis can classify text as positive, negative, or neutral, or even detect more granular emotions like joy, anger, or sadness. This task is widely used in business for understanding customer feedback, monitoring brand reputation, and analyzing social media trends. For example, a company might use sentiment analysis to gauge public opinion about a new product launch by analyzing tweets and reviews.
Text Classification
Text classification is the task of assigning predefined categories or labels to a given text. This is a supervised learning task where a model is trained on a dataset of labeled texts to learn the patterns that distinguish different categories. Common applications include spam detection (classifying emails as spam or not spam), topic labeling (categorizing news articles into sports, politics, technology, etc.), and content moderation (identifying inappropriate content). For instance, a news organization might use text classification to automatically sort incoming articles into relevant sections, saving significant manual effort.
Named Entity Recognition (NER)
Named Entity Recognition (NER) is the task of identifying and classifying named entities in text into predefined categories such as person names, organizations, locations, dates, expressions of times, quantities, monetary values, percentages, etc. NER is a crucial step in information extraction, as it helps to structure unstructured text data. For example, in the sentence “Barack Obama visited London on July 15, 2024,” an NER system would identify “Barack Obama” as a person, “London” as a location, and “July 15, 2024” as a date. NER is used in various applications, including search engines, customer support systems, and medical information extraction.
Example: Building a Sentiment Analyzer in Python Using NLTK
Let’s build a simple sentiment analyzer using Python and the Natural Language Toolkit (NLTK) library. NLTK is a powerful library for working with human language data.
Prerequisites
First, ensure you have Python and NLTK installed. If not, you can install NLTK and download its necessary data:
pip install nltk
python -m nltk.downloader allCode Example
Create a Python file named sentiment_analyzer.py:
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
# Download VADER lexicon (if not already downloaded)
try:
nltk.data.find("sentiment/vader_lexicon.zip")
except nltk.downloader.DownloadError:
nltk.download("vader_lexicon")
sia = SentimentIntensityAnalyzer()
def analyze_sentiment(text):
score = sia.polarity_scores(text)
print(f"Text: \"{text}\"")
print(f"Sentiment Scores: {score}")
if score["compound"] >= 0.05:
print("Overall Sentiment: Positive\n")
elif score["compound"] <= -0.05:
print("Overall Sentiment: Negative\n")
else:
print("Overall Sentiment: Neutral\n")
# Test cases
analyze_sentiment("This movie is absolutely fantastic! I loved every minute of it.")
analyze_sentiment("The customer service was terrible, and the product broke quickly.")
analyze_sentiment("The weather today is neither good nor bad.")
analyze_sentiment("What a brilliant idea! This will revolutionize the industry.")
analyze_sentiment("I am so disappointed with the quality of this purchase.")Explanation
- Import necessary libraries: We import
nltkandSentimentIntensityAnalyzerfromnltk.sentiment. - Download VADER lexicon: The VADER (Valence Aware Dictionary and sEntiment Reasoner) lexicon is a rule-based sentiment analysis model specifically attuned to sentiments expressed in social media. We ensure it’s downloaded.
- Initialize SentimentIntensityAnalyzer: We create an instance of
SentimentIntensityAnalyzer. analyze_sentimentfunction:- It takes a
textstring as input. sia.polarity_scores(text)returns a dictionary of sentiment scores:neg(negative),neu(neutral),pos(positive), andcompound(a normalized, weighted composite score ranging from -1 to 1).- Based on the
compoundscore, we classify the overall sentiment as Positive, Negative, or Neutral.
- It takes a
Running the Code
Save the file as sentiment_analyzer.py and run it from your terminal:
python sentiment_analyzer.pyOutput:
Text:
\"This movie is absolutely fantastic! I loved every minute of it.\"
Sentiment Scores: {"neg": 0.0, "neu": 0.41, "pos": 0.59, "compound": 0.9081}
Overall Sentiment: Positive
Text: \"The customer service was terrible, and the product broke quickly.\"
Sentiment Scores: {"neg": 0.47, "neu": 0.53, "pos": 0.0, "compound": -0.765}
Overall Sentiment: Negative
Text: \"The weather today is neither good nor bad.\"
Sentiment Scores: {"neg": 0.0, "neu": 1.0, "pos": 0.0, "compound": 0.0}
Overall Sentiment: Neutral
Text: \"What a brilliant idea! This will revolutionize the industry.\"
Sentiment Scores: {"neg": 0.0, "neu": 0.49, "pos": 0.51, "compound": 0.836}
Overall Sentiment: Positive
Text: \"I am so disappointed with the quality of this purchase.\"
Sentiment Scores: {"neg": 0.474, "neu": 0.526, "pos": 0.0, "compound": -0.6249}
Overall Sentiment: NegativeThis simple example demonstrates how NLTK and VADER can be used to quickly assess the sentiment of text, providing a foundational understanding of sentiment analysis.
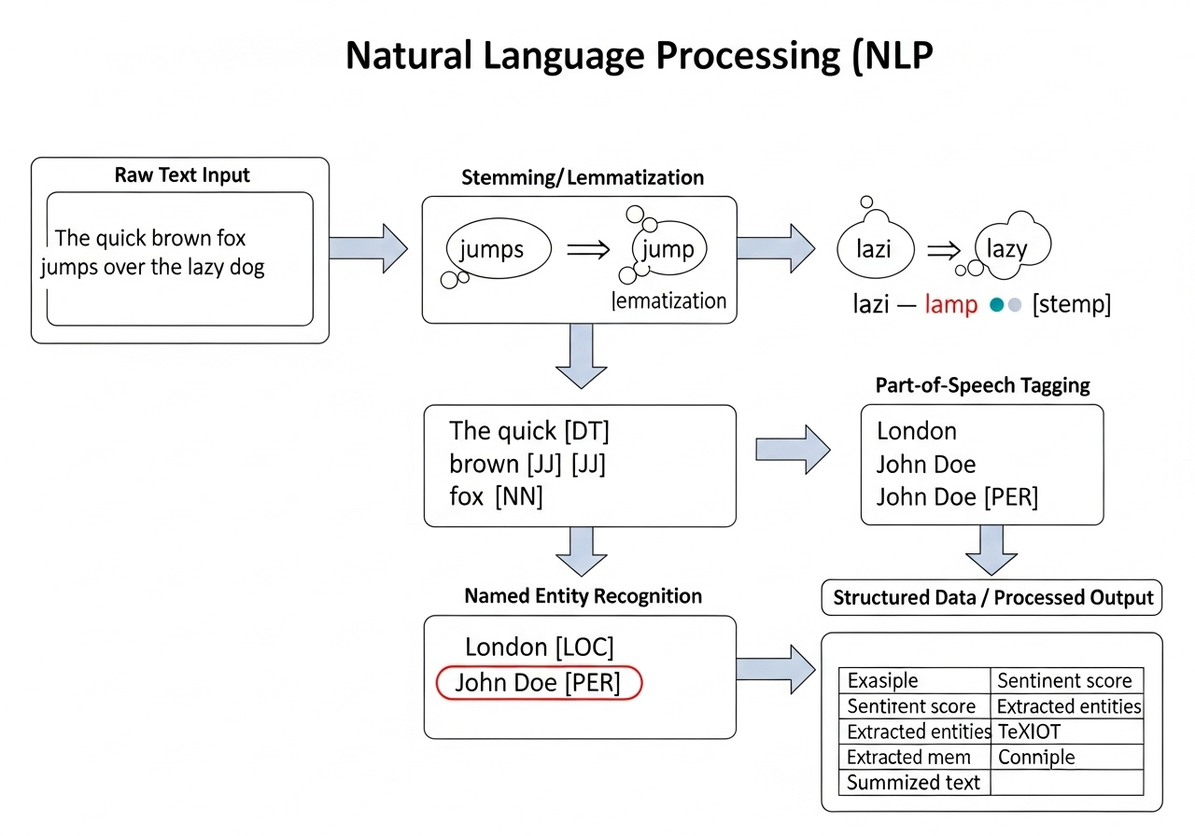
Diagram: The NLP Pipeline
To better understand the flow of text processing in NLP, consider the following diagram which illustrates a typical NLP pipeline:
This diagram visually represents the sequential steps involved in processing raw text for NLP tasks. It starts with the raw text input, which then undergoes tokenization to break it into individual words. Following this, processes like stemming or lemmatization reduce words to their base forms. Subsequent stages might include part-of-speech tagging, which identifies the grammatical role of each word, and named entity recognition, which extracts specific entities like names or locations. The ultimate goal is to transform unstructured text into structured data or a processed output that can be used for further analysis or application.
Conclusion: The Impact and Future of NLP
Natural Language Processing has emerged as a pivotal field in artificial intelligence, transforming how humans interact with technology and how we extract insights from the vast ocean of textual data. From enabling seamless communication with voice assistants to powering sophisticated search engines and sentiment analysis tools, NLP has permeated nearly every aspect of our digital lives. Its ability to bridge the gap between human language and machine understanding has unlocked unprecedented opportunities for automation, efficiency, and discovery.
The journey of NLP has been marked by significant milestones, from early rule-based systems to the current era dominated by machine learning and deep learning. The development of powerful neural network architectures, such as Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTMs), and especially Transformers, has propelled NLP capabilities to new heights. These models, trained on massive datasets, can capture intricate linguistic patterns and contextual nuances, leading to remarkable improvements in tasks like machine translation, text summarization, and question answering.
The future of NLP promises even more exciting advancements. We can anticipate further improvements in model accuracy and efficiency, enabling real-time processing of complex language. The integration of NLP with other AI domains, such as computer vision and robotics, will lead to more intelligent and context-aware systems. Ethical considerations, including bias in language models and the responsible use of NLP technologies, will also continue to be a critical area of focus. As NLP models become more sophisticated, their potential to impact industries from healthcare and finance to education and entertainment will only grow.
For beginners, the field of NLP offers a rich and rewarding area of study. Starting with fundamental concepts like tokenization and understanding common tasks such as sentiment analysis provides a solid foundation. As you delve deeper, exploring advanced topics like word embeddings, sequence-to-sequence models, and attention mechanisms will open up new possibilities. The availability of open-source libraries like NLTK, spaCy, and Hugging Face Transformers makes it easier than ever to experiment and build your own NLP applications. By embracing the complexities and continually learning, you can contribute to shaping the future of how machines understand and interact with human language.
Discussion
Loading comments...