A Deep Dive into Serverless Architectures
A Deep Dive into Serverless Architectures
Introduction to Serverless Computing
Serverless computing represents a paradigm shift in how developers build and deploy applications. It is a cloud execution model where the cloud provider dynamically manages the allocation and provisioning of servers. Unlike traditional server-based architectures where developers are responsible for managing the underlying infrastructure, serverless abstracts away these operational complexities, allowing developers to focus solely on writing code. This model is often misunderstood; the term “serverless” does not mean that servers are no longer involved. Instead, it signifies that the server management responsibilities are entirely offloaded to the cloud provider. This fundamental difference leads to significant advantages in terms of scalability, cost-efficiency, and development velocity.
In a traditional server-centric approach, even with virtual machines or containers, developers still need to provision, scale, and maintain servers. This involves estimating traffic, configuring load balancers, and ensuring high availability. Serverless computing eliminates these concerns by automatically scaling resources up or down based on demand. When a function is invoked, the cloud provider spins up the necessary resources to execute the code. When the execution is complete, those resources are de-provisioned. This event-driven, ephemeral nature is a cornerstone of serverless, enabling a pay-per-execution billing model where you only pay for the compute time consumed, often down to the millisecond.
The evolution towards serverless computing is a natural progression from earlier cloud models. Initially, Infrastructure as a Service (IaaS) provided virtualized hardware, giving users immense control but still requiring significant operational overhead. Platform as a Service (PaaS) offered a higher level of abstraction, managing operating systems and runtime environments, but still often requiring users to manage scaling and some aspects of deployment. Serverless, or Function as a Service (FaaS) and Backend as a Service (BaaS), takes this abstraction to its logical conclusion, offering maximum developer agility by completely managing the server infrastructure. This shift empowers developers to innovate faster, reduce time-to-market, and significantly lower operational costs, making it an increasingly attractive option for a wide range of applications, from web backends and data processing to chatbots and IoT solutions.
Key Concepts: FaaS, BaaS, and Cloud Providers
To truly understand serverless architectures, it’s crucial to grasp its core components: Function as a Service (FaaS) and Backend as a Service (BaaS). These two concepts form the backbone of most serverless implementations, each addressing different aspects of application development.
Function as a Service (FaaS)
FaaS is the most recognizable component of serverless computing. It allows developers to execute code in response to events without provisioning or managing servers. The code is deployed as individual functions, and the cloud provider handles all the underlying infrastructure, including server provisioning, scaling, and maintenance. These functions are typically stateless, meaning they don’t retain any data from one invocation to the next. This stateless nature promotes horizontal scalability, as any instance of the function can handle any request.
Popular FaaS offerings include:
- AWS Lambda: Amazon Web Services (AWS) Lambda is arguably the most mature and widely adopted FaaS platform. It supports various programming languages (Node.js, Python, Java, C#, Go, Ruby, PowerShell) and can be triggered by a multitude of AWS services, such as API Gateway, S3, DynamoDB, and Kinesis. Lambda functions are highly scalable and integrate seamlessly with the broader AWS ecosystem, making it a powerful choice for building event-driven applications.
- Azure Functions: Microsoft Azure Functions is Azure’s equivalent to AWS Lambda. It offers similar capabilities, supporting multiple languages and integrating with other Azure services like Azure Event Grid, Azure Cosmos DB, and Azure Storage. Azure Functions provides both consumption plans (pay-per-execution) and premium plans for more predictable performance.
- Google Cloud Functions: Google Cloud Functions is Google Cloud Platform’s (GCP) FaaS offering. It supports Node.js, Python, Go, Java, and .NET, and can be triggered by events from various GCP services, including Cloud Pub/Sub, Cloud Storage, and Firebase. Google Cloud Functions emphasizes a strong developer experience and tight integration with the GCP ecosystem.
Backend as a Service (BaaS)
While FaaS focuses on the compute aspect, BaaS provides ready-to-use backend functionalities, eliminating the need for developers to build and maintain them from scratch. These services often include databases, authentication, file storage, and push notifications. BaaS platforms allow frontend developers to directly connect their applications to these backend services, significantly accelerating development.
Common BaaS examples include:
- Firebase (Google): Firebase is a comprehensive mobile and web application development platform that offers a suite of BaaS services, including real-time databases (Cloud Firestore, Realtime Database), authentication, cloud storage, hosting, and cloud messaging. It’s particularly popular for building single-page applications (SPAs) and mobile apps.
- AWS Amplify: AWS Amplify is a set of tools and services that enables developers to build scalable full-stack applications powered by AWS. It provides a framework for building app backends, connecting to data sources (like AWS AppSync for GraphQL APIs), and integrating with other AWS services for authentication, storage, and analytics.
- Azure Mobile Apps: Part of Azure App Service, Azure Mobile Apps provides a backend for mobile applications, offering features like offline data sync, push notifications, and authentication with various identity providers.
In a typical serverless architecture, FaaS and BaaS often work hand-in-hand. For instance, a web application (frontend) might directly interact with a BaaS for user authentication and data storage, while certain complex business logic or data processing tasks are handled by FaaS functions triggered by events from the BaaS or other services. This combination allows for highly decoupled, scalable, and cost-effective applications.
Benefits of Serverless
Serverless computing offers a compelling set of advantages that drive its increasing adoption across various industries. These benefits primarily stem from the abstraction of infrastructure management, leading to significant improvements in cost, scalability, and operational efficiency.
Cost-Efficiency: Pay-per-Execution
One of the most attractive aspects of serverless is its unique billing model: pay-per-execution. Unlike traditional server models where you pay for provisioned server capacity regardless of actual usage, serverless charges you only for the compute time consumed when your functions are actively running. This granular billing, often down to the millisecond, can lead to substantial cost savings, especially for applications with fluctuating or infrequent traffic patterns. For example, a function that runs for 100 milliseconds and is invoked a million times a month would cost significantly less than maintaining a dedicated server running 24/7 to handle the same workload. This eliminates the need for over-provisioning resources to handle peak loads, as the cloud provider automatically scales to meet demand, ensuring you only pay for what you use.
Automatic Scalability
Serverless platforms inherently provide automatic and elastic scalability. When a function is invoked, the cloud provider automatically provisions and manages the necessary resources to execute it. If there’s a sudden surge in demand, the platform automatically scales out by running multiple instances of your function concurrently. Conversely, when demand drops, resources are automatically de-provisioned. This eliminates the need for manual scaling configurations, load balancers, and complex auto-scaling groups. Developers no longer have to worry about capacity planning or infrastructure bottlenecks, allowing their applications to seamlessly handle anything from a few requests per day to millions of requests per second without any manual intervention. This level of elasticity is difficult and expensive to achieve with traditional server-based architectures.
Reduced Operational Overhead
By abstracting away server management, serverless significantly reduces the operational burden on development teams. Developers are freed from tasks such as server provisioning, patching, operating system maintenance, security updates, and capacity planning. The cloud provider handles all these responsibilities, allowing development teams to focus their time and resources on writing code, building features, and innovating. This shift in focus accelerates development cycles, improves developer productivity, and reduces the overall time-to-market for new applications and features. The reduced operational overhead also translates to fewer human errors and a more stable, secure environment, as the cloud provider is responsible for maintaining the underlying infrastructure at a high standard.
Faster Time-to-Market
The combination of reduced operational overhead and automatic scalability directly contributes to a faster time-to-market. With serverless, developers can rapidly prototype, deploy, and iterate on new features without waiting for infrastructure provisioning or complex deployment pipelines. The modular nature of functions also encourages a microservices-based approach, where small, independent services can be developed and deployed independently. This agility allows businesses to respond quickly to market changes, experiment with new ideas, and deliver value to users at an accelerated pace. The simplified deployment model, often involving just uploading code, further streamlines the development pipeline, making it easier to get applications into production quickly and efficiently.
Challenges and Considerations
While serverless computing offers numerous benefits, it also comes with its own set of challenges and considerations that developers and organizations need to be aware of before fully embracing the paradigm. Understanding these potential drawbacks is crucial for making informed architectural decisions and mitigating risks.
Cold Starts
One of the most frequently discussed challenges in serverless computing is the concept of “cold starts.” A cold start occurs when a function is invoked after a period of inactivity, and the cloud provider needs to initialize a new execution environment for that function. This initialization process involves downloading the function code, setting up the runtime environment, and executing any initialization logic. During this time, the function’s response time can be noticeably slower, ranging from a few hundred milliseconds to several seconds, depending on the language, dependencies, and cloud provider. For latency-sensitive applications, cold starts can negatively impact user experience. While cloud providers have made significant strides in reducing cold start times, and techniques like “provisioned concurrency” or “keeping functions warm” can mitigate the issue, it remains a factor to consider, especially for interactive applications.
Vendor Lock-in
Adopting a serverless architecture often means tightly integrating with a specific cloud provider’s ecosystem. Each major cloud provider (AWS, Azure, Google Cloud) has its own FaaS and BaaS offerings, along with proprietary services and APIs. While this integration can offer powerful capabilities and seamless workflows within that ecosystem, it can also lead to vendor lock-in. Migrating a serverless application from one cloud provider to another can be a complex and time-consuming process, as it often requires re-architecting components, rewriting code to adapt to different APIs, and reconfiguring deployment pipelines. This potential for lock-in can be a concern for organizations that prioritize multi-cloud strategies or want the flexibility to switch providers in the future. Careful planning and the use of cloud-agnostic frameworks or design patterns can help reduce the degree of vendor lock-in.
Debugging and Monitoring
Debugging and monitoring serverless applications can be more challenging compared to traditional monolithic or even microservices architectures. The ephemeral nature of functions, distributed execution across multiple services, and the lack of direct server access make it difficult to trace requests, inspect logs, and identify performance bottlenecks. Traditional debugging tools and techniques designed for long-running processes are often not directly applicable. While cloud providers offer their own monitoring and logging services (e.g., AWS CloudWatch, Azure Monitor, Google Cloud Logging), gaining a holistic view of an entire serverless application can require integrating with specialized third-party tools. Correlating logs across multiple functions and services, understanding the flow of events, and reproducing issues can be complex, demanding a different approach to observability.
Resource Limits and Execution Duration
Serverless functions typically have predefined resource limits (e.g., memory, CPU) and maximum execution durations. These limits are in place to ensure fair resource allocation across a multi-tenant environment and to prevent runaway functions. While these limits are generally generous enough for most common use cases, they can pose challenges for computationally intensive tasks, long-running processes, or batch jobs. For example, a function designed to process a large video file or perform complex machine learning inferences might hit memory or time limits. Developers need to design their functions to be idempotent and capable of resuming from where they left off, or consider alternative services for such workloads. Understanding and designing within these constraints is crucial for successful serverless adoption.
Example: Building a Serverless API with AWS Lambda and API Gateway
Let’s walk through a practical example of building a simple serverless API using AWS Lambda and Amazon API Gateway. This example will demonstrate how these two services work together to create a scalable and cost-effective backend for a web application. We’ll create an API endpoint that, when invoked, triggers a Lambda function to store data in an Amazon DynamoDB table.
Prerequisites
Before you begin, ensure you have:
- An AWS account.
- AWS CLI configured with appropriate permissions.
- Node.js and npm installed.
Step 1: Create a DynamoDB Table
First, we need a database to store our data. We’ll use Amazon DynamoDB, a fully managed NoSQL database service that integrates seamlessly with Lambda.
aws dynamodb create-table \
--table-name MyServerlessTable \
--attribute-definitions \
AttributeName=id,AttributeType=S \
--key-schema \
AttributeName=id,KeyType=HASH \
--provisioned-throughput \
ReadCapacityUnits=5,WriteCapacityUnits=5This command creates a DynamoDB table named MyServerlessTable with id as its primary key.
Step 2: Create an IAM Role for Lambda
Our Lambda function needs permissions to write to the DynamoDB table and to create CloudWatch logs. Create an IAM role with the necessary policies.
First, create a trust policy file lambda-trust-policy.json:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}Then, create the role:
aws iam create-role \
--role-name LambdaDynamoDBRole \
--assume-role-policy-document file://lambda-trust-policy.jsonAttach policies for DynamoDB access and CloudWatch logs:
aws iam attach-role-policy \
--role-name LambdaDynamoDBRole \
--policy-arn arn:aws:iam::aws:policy/AmazonDynamoDBFullAccess
aws iam attach-role-policy \
--role-name LambdaDynamoDBRole \
--policy-arn arn:aws:iam::aws:policy/CloudWatchLogsFullAccessMake sure to wait a few seconds for the IAM role to propagate.
Step 3: Write the Lambda Function Code
Create a file named index.js for your Lambda function:
const AWS = require("aws-sdk");
const docClient = new AWS.DynamoDB.DocumentClient();
exports.handler = async (event) => {
console.log("Received event:", JSON.stringify(event, null, 2));
const { id, data } = JSON.parse(event.body);
const params = {
TableName: "MyServerlessTable",
Item: {
id: id,
data: data,
timestamp: new Date().toISOString(),
},
};
try {
await docClient.put(params).promise();
return {
statusCode: 200,
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ message: "Data stored successfully!" }),
};
} catch (error) {
console.error("Error storing data:", error);
return {
statusCode: 500,
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ message: "Error storing data", error: error.message }),
};
}
};This Node.js function expects a JSON body with id and data fields, and it stores them in our DynamoDB table.
Step 4: Create the Lambda Function
Package your index.js into a zip file and create the Lambda function.
zip function.zip index.js
aws lambda create-function \
--function-name MyServerlessFunction \
--runtime nodejs18.x \
--role arn:aws:iam::<YOUR_AWS_ACCOUNT_ID>:role/LambdaDynamoDBRole \
--handler index.handler \
--zip-file fileb://function.zip \
--memory-size 128 \
--timeout 30Replace <YOUR_AWS_ACCOUNT_ID> with your actual AWS account ID. You can find this in the AWS Management Console.
Step 5: Create an API Gateway REST API
Now, we’ll create an API Gateway to expose our Lambda function via an HTTP endpoint.
aws apigateway create-rest-api \
--name MyServerlessAPI \
--description "API for MyServerlessFunction"Note down the id of the created API from the output (e.g., abcdef123).
Step 6: Create a Resource and Method
Create a resource (e.g., /items) and a POST method for it.
# Get the root resource ID
ROOT_RESOURCE_ID=$(aws apigateway get-resources \
--rest-api-id <YOUR_API_ID> \
--query "items[?path=='/'].id" \
--output text)
aws apigateway create-resource \
--rest-api-id <YOUR_API_ID> \
--parent-id $ROOT_RESOURCE_ID \
--path-part itemsNote down the id of the newly created /items resource (e.g., xyz789).
Now, create the POST method:
aws apigateway put-method \
--rest-api-id <YOUR_API_ID> \
--resource-id <YOUR_ITEMS_RESOURCE_ID> \
--http-method POST \
--authorization-type NONE \
--request-models "{\"application/json\": \"Empty\"}"Step 7: Integrate API Gateway with Lambda
Connect the POST method to your Lambda function.
aws apigateway put-integration \
--rest-api-id <YOUR_API_ID> \
--resource-id <YOUR_ITEMS_RESOURCE_ID> \
--http-method POST \
--type AWS_PROXY \
--integration-http-method POST \
--uri arn:aws:apigateway:<YOUR_AWS_REGION>:lambda:path/2015-03-31/functions/arn:aws:lambda:<YOUR_AWS_REGION>:<YOUR_AWS_ACCOUNT_ID>:function:MyServerlessFunction/invocationsReplace <YOUR_AWS_REGION> with your AWS region (e.g., us-east-1).
Grant API Gateway permission to invoke the Lambda function:
aws lambda add-permission \
--function-name MyServerlessFunction \
--statement-id ApiGatewayInvoke \
--action lambda:InvokeFunction \
--principal apigateway.amazonaws.com \
--source-arn "arn:aws:execute-api:<YOUR_AWS_REGION>:<YOUR_AWS_ACCOUNT_ID>:<YOUR_API_ID>/*/*/*"Step 8: Deploy the API
Deploy the API to a stage (e.g., prod).
aws apigateway create-deployment \
--rest-api-id <YOUR_API_ID> \
--stage-name prodThe output will include the invokeUrl, which is your API endpoint (e.g., https://<YOUR_API_ID>.execute-api.<YOUR_AWS_REGION>.amazonaws.com/prod/items).
Step 9: Test the API
Use curl to test your new serverless API.
curl -X POST -H "Content-Type: application/json" \
-d "{\"id\": \"123\", \"data\": \"Hello Serverless!\"}" \
https://<YOUR_API_ID>.execute-api.<YOUR_AWS_REGION>.amazonaws.com/prod/itemsYou should receive a 200 OK response with the message “Data stored successfully!”. You can also verify the data in your DynamoDB table.
Diagram: A Visual Representation of a Serverless Architecture
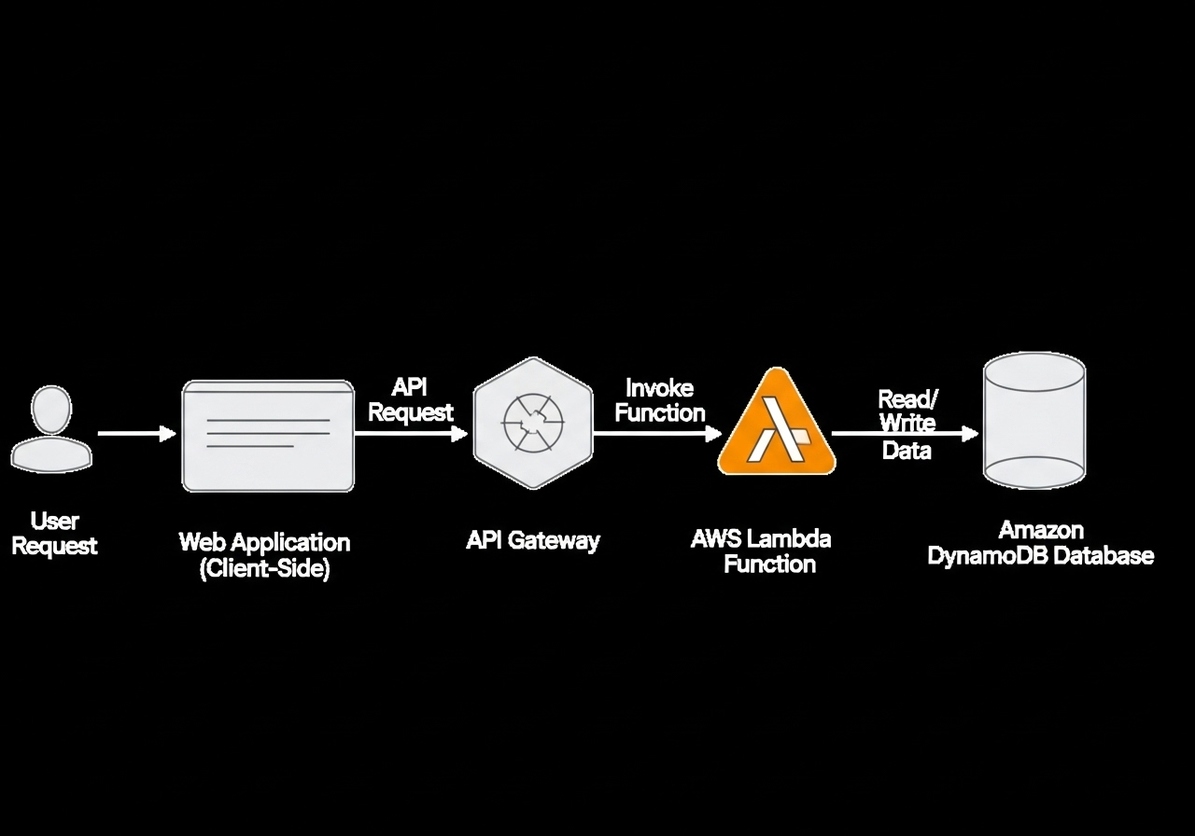
To further illustrate the flow of data and interactions in a serverless application, consider the following diagram:
This diagram visually represents the example we just built. A user’s request initiates from a web application (client-side). This request is then routed through the API Gateway, which acts as the entry point for the API. The API Gateway, in turn, invokes the AWS Lambda function. The Lambda function executes the business logic, which in this case involves interacting with an Amazon DynamoDB database to read or write data. The arrows clearly show the unidirectional flow of the request and the bidirectional interaction with the database, highlighting the decoupled nature of each component.
Conclusion: The Future of Serverless and When to Adopt It
Serverless computing is not just a fleeting trend; it represents a fundamental shift in cloud application development, offering a powerful model for building scalable, cost-effective, and highly available applications. Its ability to abstract away infrastructure management empowers developers to focus on delivering business value, accelerating innovation and reducing operational burdens.
The future of serverless is bright, with continuous advancements from cloud providers in areas like cold start optimization, improved tooling for debugging and monitoring, and broader integration with various services. We can expect to see more sophisticated use cases emerge, extending beyond simple APIs to complex event-driven systems, real-time data processing pipelines, and even machine learning inference at the edge.
However, serverless is not a silver bullet for all use cases. It excels in scenarios characterized by:
- Event-driven workloads: Applications that respond to specific events, such as API requests, database changes, file uploads, or scheduled tasks.
- Variable and unpredictable traffic: Workloads that experience significant spikes and lulls in demand, where automatic scaling provides immense cost benefits.
- Microservices architectures: Building highly decoupled, independent services that can be developed, deployed, and scaled independently.
- Rapid prototyping and iteration: When speed to market and frequent deployments are critical.
Conversely, serverless might be less suitable for:
- Long-running, computationally intensive tasks: While functions can be configured for longer durations, very long-running processes might be more cost-effective and manageable on dedicated compute instances.
- Applications with strict latency requirements where cold starts are unacceptable: Although cold starts are improving, they can still be a factor for extremely low-latency applications.
- Legacy applications requiring significant refactoring: Migrating existing monolithic applications to a serverless architecture can be a substantial undertaking.
- Workloads with highly consistent and predictable traffic: For constant, high-volume traffic, the cost benefits of serverless might diminish compared to optimized provisioned resources.
Ultimately, the decision to adopt serverless should be based on a careful evaluation of your application’s specific requirements, traffic patterns, team expertise, and long-term strategic goals. When applied judiciously, serverless computing can unlock unprecedented levels of agility, efficiency, and scalability, enabling organizations to build the next generation of cloud-native applications with greater ease and confidence. By understanding its benefits and challenges, developers can harness the power of serverless to create innovative and resilient solutions that drive business success.
Discussion
Loading comments...